
El IMEI (International Mobile System Equipment Identity) es un número único que identifica a cada dispositivo móvil en el mundo.…

En Malavida encontrarás toda la actualidad sobre apps Android e iOS, el mejor software y lo último en tecnología.
El IMEI (International Mobile System Equipment Identity) es un número único que identifica a cada dispositivo móvil en el mundo.…

La UFC, o Ultimate Fighting Championship, es la mayor empresa de artes marciales mixtas (MMA) del mundo. Con todos los eventos y espectáculos…

Max, la nueva plataforma de Warner Bros. Discovery, te ofrece una experiencia renovada con más contenido y una personalización…

Las stories o historias de Instagram se han convertido en uno de los principales reclamos de la red social de Meta. Con la excusa de su…

El cifrado de extremo a extremo en WhatsApp es una capa de seguridad adicional que protege tus mensajes de ser interceptados por terceros. Cuando…

Android TV es el sistema operativo de Google diseñado específicamente para televisores inteligentes. El mismo te da acceso a un…

En Temu, encontrarás una gran variedad de productos de alta calidad a precios competitivos, desde ropa y productos de belleza hasta…

La memoria RAM es como la memoria a corto plazo de tu móvil: guarda las tareas y los datos que las apps necesitan para funcionar al instante.…

Los Servicios de Google Play o Google Play Services son una aplicación importante de Android. Tienen presencia propia en Google Play, como una…

Tinder es una app para encontrar personas con intereses similares y, con suerte, conseguir un match. Sin embargo, hacer match en Tinder no es tan…

¿Programas, series, películas, deportes? Hoy en día es muy sencillo tener un pequeño televisor en el bolsillo gracias a…

En esta guía te vamos a explicar cómo ocultar tu foto de perfil de WhatsApp a tus contactos. Primero, hablamos…

En los últimos años, el robo de datos digitales en los medios online se ha convertido en un problema a la orden del día. Por…

En Tinder, la búsqueda del amor es como un juego de cartas donde nunca sabes qué mano te tocará. Pero, ¿y si existiera…

Friday Night Funkin' es un videojuego que te invita a un desafío musical sin igual, donde Boyfriend, nuestro protagonista, deberá…

Cómo ver la TV desde el ordenador Ver la televisión en el ordenador es una cosa muy sencilla, gracias tanto a la oferta que existe en…

En esta guía te vamos a explicar qué pasos debes seguir para actualizar los Servicios de Google Play. Recuerda que son aquellos…

Kodi es un potente y versátil centro multimedia puede reproducir cualquier contenido que tengas alojado en tu ordenador. Música,…

Los juegos de simulación de granjas causaron sensación en los años 2010. Aunque el fenómeno de masas surgió en…

Aunque en origen la idea era que los usuarios de Wallapop realizaran la compraventa de artículos en mano, esto limitaba mucho las…

Steam es una de las principales plataformas de videojuegos online para PC. En los últimos años se ha convertido en todo un referente y…

Si te pones a pensar, conseguir el amor en Tinder es como buscar una aguja en un pajar. Y si encima te topas con perfiles falsos o personas que no…

Si eres seguidor de los campeonatos de motociclismo, seguramente ya sabrás que Atresmedia ha llegado a un acuerdo con MotoGP y DAZN para…

En esta guía te vamos a explicar todo acerca de Telegram Web, un sistema que te permite acceder a tus chats desde cualquier dispositivo,…

Tinder es una de las mejores aplicaciones de citas y para ligar, pero para darte de alta, normalmente te pide que proporciones tu número de…

Spotify es una de las plataformas más populares para escuchar música por internet. Ya sea pagando una suscripción o de manera…

Friday Night Funkin' es un videojuego de ritmo popular que ha ganado una gran base de seguidores debido a su estilo underground y su música…

En esta guía te vamos a explicar cuáles son todas las opciones disponibles en Google Maps para Android a la hora…

Como sucede en la mayoría de canales de venta online, en Temu también pueden estafarte. Eso no significa que esta…

Que Waze es una herramienta indispensables para muchos conductores es innegable. Uno de sus puntos fuertes es su comunidad, que informa de…

La vista previa de enlaces de WhatsApp es una función curiosa que consiste en mostrar información y una imagen sobre dicho enlace.…

Tinder, la app de citas que está en boca de todos, se ha convertido en el lugar favorito de muchos solteros. Sin embargo, para sacarle todo el…

Hoy en día, prácticamente cualquier persona puede crear un vídeo deslumbrante con una apliación de edición de…

Los fanáticos del fútbol suscritos a Amazon Prime Video están de enhorabuena, porque ahora también pueden disfrutar de su…

Los amantes de los videojuegos contamos con una variedad y cantidad de títulos a los que jugar cada vez mayor. Y jugar en PC suele ser una de…

Si estás soltero y buscas una forma moderna y divertida de conseguir el amor, entonces debes conocer Tinder, una de las mejores aplicaciones…

Uno de los problemas más habituales en los teléfonos móviles es la falta de espacio. Sin embargo, muchas veces nuestro…

En esta guía te contamos qué son los Servicios de Google Play y para qué sirven. Además, te vamos a explicar por…

Solo hace unos años que convivimos con dispositivos GPS, aplicaciones de mapas y navegación y otras herramientas digitales similares.…

Los atajos de teclado para Excel en macOS te permiten ejecutar acciones básicas y avanzadas de la aplicación con…
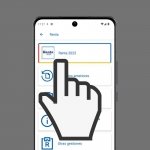
La declaración de la Renta es una obligación fiscal que deben cumplir los ciudadanos españoles que hayan obtenido ingresos…

Wallapop es una plataforma muy popular para comprar y vender productos de segunda mano. Con su enorme variedad de artículos, es fácil…
Para que un teléfono móvil funcione, un gran número de ficheros y elementos funcionan en segundo plano. Y aunque seguramente ya…

En esta guía te vamos a explicar todo lo que necesitas saber sobre Temu. Te mostramos qué es exactamente esta plataforma,…

Gmail es el servicio electrónico de correo electrónico de Google y una de las apps más utilizadas a nivel general, ya sea para…

La confirmación de lectura es una opción presente en muchas aplicaciones de mensajería, como WhatsApp, Telegram e Instagram.…

Omegle es una de esas plataformas que ha funcionado durante tanto tiempo que parece que ha estado con nosotros toda la vida. Gracias a ella, son…

Friday Night Funkin' es un videojuego musical que te reta a demostrar tus habilidades rítmicas en batallas de rap y baile contra diferentes…

Los atajos de teclado en Word te van a ayudar a trabajar más rápido. En esencia, son combinaciones de teclas que te permiten…

En esta guía te vamos a explicar cómo puedes buscar por coordenadas en Google Maps. Te lo contamos todo acerca de esta útil…

Avast, uno de los antivirus más populares y confiables, ofrece una amplia protección contra las amenazas cibernéticas. Sin…

Android TV es la versión de Android específica para televisores inteligentes y dispositivos que se conectan al televisor. Aunque su…

Telegram ha sido una opción popular durante mucho tiempo, sobre todo por su enfoque único en la privacidad y la libertad de…

En los últimos años, Wallapop se ha convertido en una de las principales plataformas de compra y venta de artículos de segunda…

Aunque a primera vista solo veas una pantalla con un montón de aplicaciones modernas y un bonito fondo de pantalla, en el interior de tu…

Los bloqueos y restricciones son una realidad en muchos países, y Telegram no es una excepción. Si estás atrapado en uno de esos…

Minecraft es, a día de hoy, el juego que ofrece mayor libertad a su público. Las opciones que nos da el título de Mojang son…
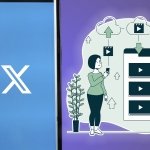
X (Twitter), la red social reconocida por su rápida difusión de noticias, opiniones y contenido multimedia, es el lugar perfecto para…

La inteligencia artificial está en todas partes. A veces, de manera visible. Pero otras, se integra tan bien en una página o…

Aunque todavía hay muchas personas que prefieren leer en papel, nadie puede negar que el Kindle de Amazon se ha convertido en un dispositivo…

Las llamadas de X (Twitter) son una forma de conectar con tus amigos y seguidores en tiempo real. Pero si no tienes cuidado, cualquiera puede…

Allá por los años 90, Bandai revolucionó el mercado de las mascotas virtuales con el mítico Tamagotchi. El éxito…

En esta guía te contamos cómo puedes saber si alguien está conectado en Signal. Además, hablamos sobre la privacidad…

En esta guía te contamos todos los pasos que debes seguir para activar y desactivar el límite de velocidad en Google…

En esta guía te vamos a contar cómo subir archivos a MEGA y compartirlos con otros. Esta plataforma para guardar archivos en la…

TikTok es una plataforma gratuita en la que subir y ver videos de corta duración, hacer directos y conocer gente con tus mismos intereses…

Hace ya algún tiempo, WhatsApp implementó una funcionalidad para enviar imágenes que solo se pueden abrir una vez. Cuando el…

Google ofrece a todos los usuarios 15 GB de almacenamiento gratuito, un espacio que se divide entre Gmail, Google Drive y Google Fotos. Aunque se…

Instagram tiene millones de usuarios. Es probable que estés entre ellos. Y aunque la aplicación está pensada para funcionar en…

WhatsApp, una de las aplicaciones de mensajería más populares del mundo, ofrece diferentes opciones para garantizar la seguridad y la…

Filmin es una plataforma de VOD que opera en España y se creó con el apoyo de distribuidoras independientes del país. En su…

Aunque el término "supergrupo" ya no se utiliza oficialmente en Telegram, las características avanzadas que lo definían siguen…

No cabe duda que uno de los mejores MODs de WhatsApp es WhatsApp Plus APK. Sin embargo, no significa que no dispongamos de alternativas de gran…

Google Fotos es un servicio de almacenamiento en la nube que ofrece Google de forma gratuita a los usuarios. De esta forma, la app guarda una copia…

Si te hablan de la canción ‘Physical’, ¿piensas en el tema de Olivia Newton John o en el de Dua Lipa? A veces es…

En esta guía te vamos a explicar dos formas para saber cuánto dinero te has gastado en Amazon. Primero, te mostramos qué…

En esta guía te vamos a explicar cuáles son los mejores trucos y consejos para limitar el tiempo de uso de TikTok. Primero, te…

Google Fotos es una eficiente app de almacenamiento en la nube de Google que sirve para guardar y organizar automáticamente una copia de todas…

Las redes sociales se han diseñado para que los usuarios se comuniquen e interaccionen entre sí. Pero, al igual que en la vida real,…

Entre los usuarios de Android que usan MODs de WhatsApp, uno de los más descargados y utilizados es WhatsApp Plus. A pesar de no ser una…